
In business management, product lifecycle is broken into 4 stages with the distinct pattern of sales over time: introduction, growth, mature, and decline. In the diagram below, I adapt the classic product lifecycle curve to show the engineering load over time in machine learning (ML): from model development to maintenance. Managing and coordinating different stages in ML lifecycle presents pressing challenges for ML practitioners.
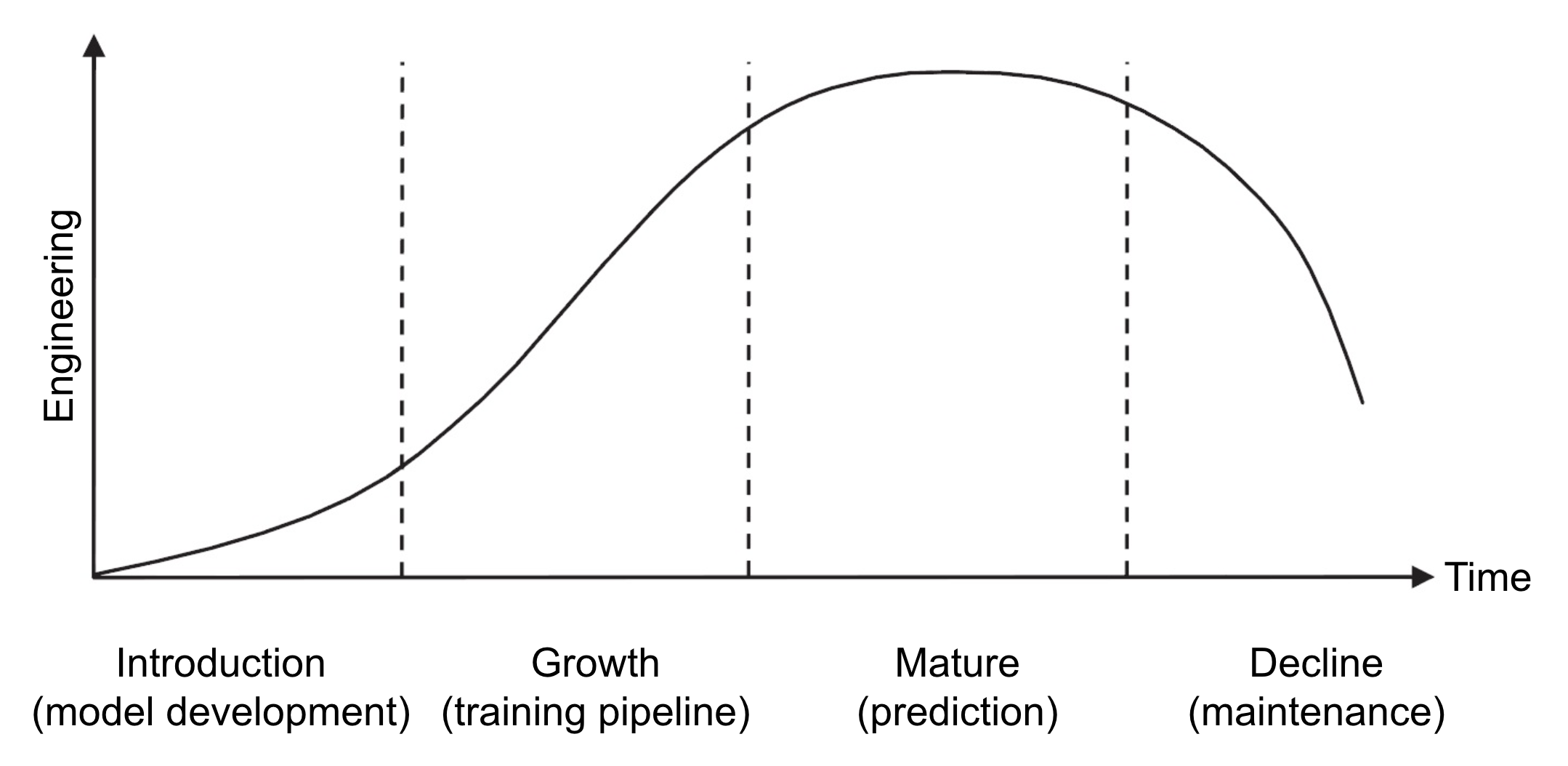
Table of Contents
The 4 stages of ML Lifecycle
As summarized by Professor Joseph E. Gonzalez in the MLSys course, ML lifecycle can be broken into 3 major stages (see the diagram below): model development, training pipeline, and inference (prediction). I would add a 4th stage: maintenance, which might sound trivial, yet occasionally, can become rather time consuming.
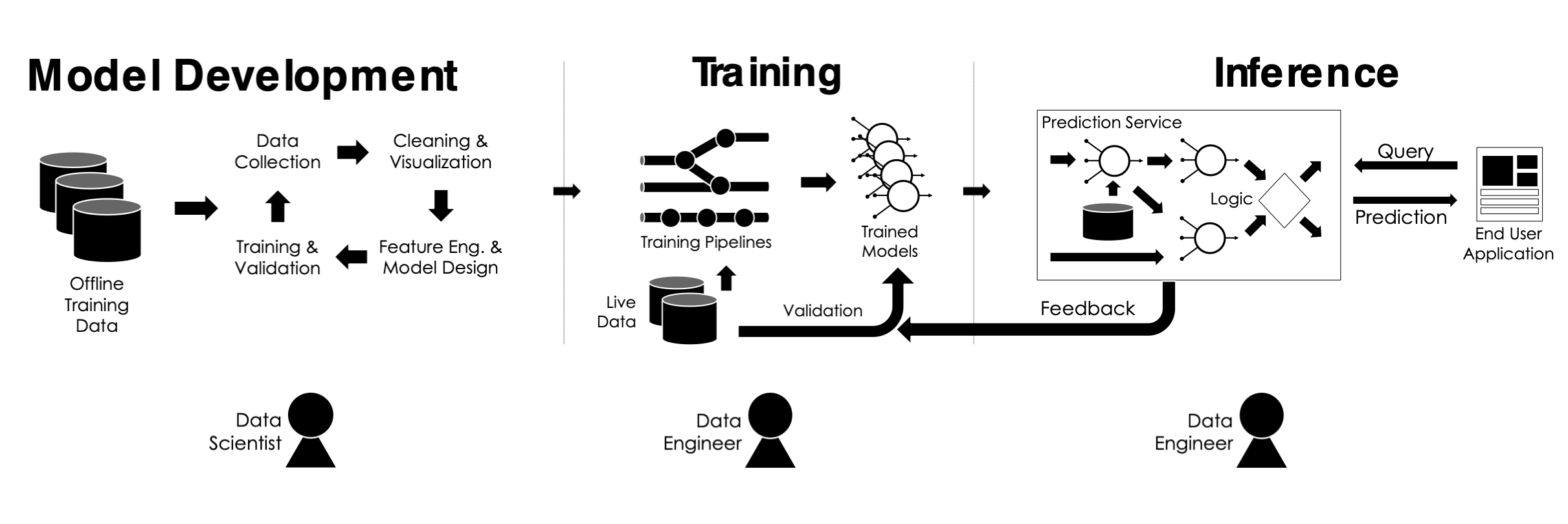
Model development
When I was in school, model development is what I knew as the field of “data science”, and Jupyter notebook with all sorts of Python packages is my favorite environment for model training and visualization.
While I still use Jupyter notebook now for model development and experimentation, there are additional challenges compared with school projects.
The primary challenge is DATA. In school projects (and Kaggle projects), the training data is prepared for us, usually in a manageable sample size.
In the real world, the raw data may be stored at multiple sources depending on company specific data management system. We may have to pull data from AWS, Google Cloud Storage, BigQuery, BigTable, Hadoop, etc, in an ad-hoc manner for experiments. Sometimes in order to collect the data we need, such as a particular type of user behavior, we may have to ask data engineers, front/backend developers to implement and enable new data ingestion and collection features.
In order to create a training data table with various features, we may have to join the raw data. How can we make sure features from different data sources are up-to-date and have the correct version? Which platform can we use to join data A from GCS to data B from BigQuery? What is the desired sample size to run a quick experiment without using all of the data?
Before we even open a Jupyter notebook, we may have to spend quite some time communicating with other teams about what data and features we are looking for, how much data we need, and in which format.
Once the offline training data is ready, it is finally time to use our favorite ML libraries (sklearn, igraph, keras, tensorflow, pytorch, spark, etc) to do feature engineering, train and tune models.
Training pipeline
After several days maybe weeks of model development in Jupyter notebook, we identify a few good handcrafted features, train a tuned neural net, and achieve a high F1 score. What’s next? Can we directly export and save the trained model in a serialized format (such as pickle or pb), and ship the model?
That’s what I thought before: we already have a good model, what else needs to be done?
In fact, there is a giant gap between the model created from model development and the actual model used in production.
First, data freshness. The saved model from model development is trained on offline data (usually a smaller sample size). We need to retrain the model on fresh data in order to capture the dynamics of real world data. Also, in a production environment, we could utilize high-performance GPU on the cluster to train on larger amount of data.
Second, reproducible data workflow. In model development, we usually perform ad-hoc data engineering to create the training data, while in production, we may want to run data engineering daily or hourly. It is crucial to capture the data dependencies to ensure the upstream data is available before proceeding to model training. Workflow orchestration and scheduling tools such as Airflow and Luigi are widely used.
Third, notebook v.s. IDE. Although notebook environment is interactive and visually appealing, it is difficult to debug and run tests in a notebook. It is important to adopt the best practice in software engineering and use a test-driven development approach in ML projects.
Fourth, language barrier. It is not uncommon that model developed in Jupyter notebook is written in Python with a new package while the model to be implemented in production has to be written in Scala or Java without the corresponding packages. When this happens, is it the responsibility of the model developer to try a different model, the pipeline developer to build the new model from scratch in Java, or the team lead to make a decision and end the project?
At first glance, the gap between model development and training pipeline would result in repeated work from different people. Indeed, from my experience, if a company draws a solid line between these 2 stages and assign them to different teams: data scientists on model development, and data engineers on training pipeline, each team may feel disconnected to the whole ML lifecycle. A hybrid approach – the same person or team is working on both model development AND pipelining – not only enables quick iteration and transition between the 2 stages, but also allows ML practitioners to always think about online production environment while doing offline development.
In addition, online production environment brings additional opportunities for model improvement: model and hyperparameters from the previous training session may be used in the present training as a warm start.
As you may tell, the training pipeline stage requires an increasing amount of engineering work as the project proceeds. Unlike traditional software engineering projects, ML systems are usually not well abstracted and could incur heavy tech debts.
Prediction
Now that we have a reproducible pipeline that generates a trained model on fresh data, it is time to use the model to make predictions.
First, we need to make sure all the features used in model training is available during prediction. There are cases when we train a very decent model with offline data and only later realize some of the high importance features are not present during prediction.
Second, we need to always evaluate the performance of model on the prediction data and monitor train-serve data drift. Our model will not perform well if the data during prediction behave drastically different from the data used in training.
Third, if we are making prediction in batch, we could use the same framework as in the training pipeline. If we are making prediction in real time, additional serving infrastructure is needed. Either there is a designated backend engineering team to build the serving infrastructure, or the ML practitioners would be involved in creating the serving pipeline to make sure a good trade off between model prediction performance, latency, and cost.
The prediction stage requires deep engineering expertise.
Maintenance
Once the whole pipeline is up and running, the system also needs regular monitoring, debugging, and maintenance. Package upgrades (such as the end of Python 2 support), missing data dependencies, and unexpected traffic can all cause the workflow to misbehave or fail.
As the system enters the maintenance stage, ML practitioners can start another cycle of model development, or iterate on existing workflow to improve model performance.
Industry ML platform solutions
In order to manage and automate ML lifecycle, iterate and transition fast from research to production, many companies develop their own ML platforms.
| ML platform | Company | Additional features | Link |
|---|---|---|---|
| Michelangelo | Uber | Bayesian optimization as a service | https://eng.uber.com/michelangelo/ |
| FBLearner Flow | View past experiments and results | https://engineering.fb.com/core-data/introducing-fblearner-flow-facebook-s-ai-backbone/ | |
| DeepBird | DeepRecord data format | https://blog.twitter.com/engineering/en_us/topics/insights/2018/twittertensorflow.html | |
| MLflow | Databrick | Open source for any ML library | https://mlflow.org/ |
| Kubeflow | Deployment on Kubernetes | https://www.kubeflow.org/ | |
| Kubeflow-based Paved Road | Spotify | Centralized Kubeflow platform | https://labs.spotify.com/2019/12/13/the-winding-road-to-better-machine-learning-infrastructure-through-tensorflow-extended-and-kubeflow/ |