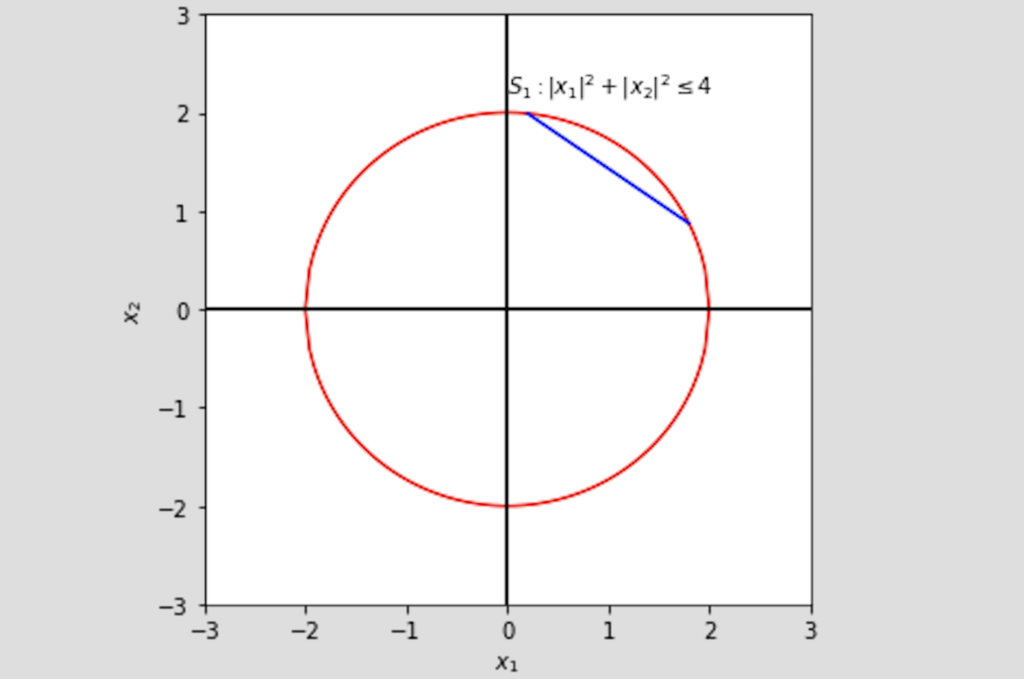
In machine learning, we are often dealing with high-dimension data. For convenience, we often use matrix to represent data. Numerical optimization in machine learning often involves matrix transformation and computation. To make matrix computation more efficiently, we always factorize a matrix into several special matrices such as triangular matrices and orthogonal matrices. In this post, I will review essential concepts of matrix used in machine learning.