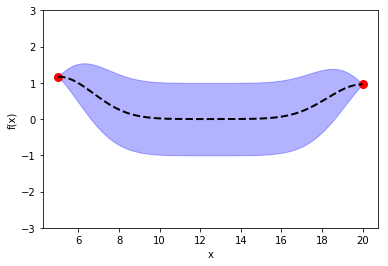
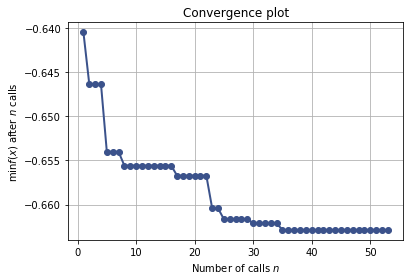
In the previous post, I introduced Bayesian Optimization for black-box function optimization such as hyperparameter tuning. It is now time to look under the hood and understand how the magic happens.
In the previous post, I introduced Bayesian Optimization for black-box function optimization such as hyperparameter tuning. It is now time to look under the hood and understand how the magic happens.
In machine learning models, we often need to manually set various hyperparameters such as the number of trees in random forest and learning rate in neural network. In traditional optimization problems, we can rely on gradient-based approaches to compute optimum. However, hyperparameter tuning is a black box problem and we usually do not have an expression for the objective function and we do not know its gradient. In this post, I will discuss different approaches for hyperparameter tuning and how we can learn to learn.

声明:本文作者最近也开设了个人博客(https://yaqiongchen.com/),如有问题和评论,请直接进入原作者的博客 北美博士的咨询申请之路。这里的评论已关。
这篇稿子应博主Ju的邀约而写,主要是总结一下北美博士找咨询工作的经验和教训。我的背景是国内Top2本科,哥大生物专业博士,下个月入职一家咨询公司的New York Office。在求职期间得到了很多的帮助,希望也能尽一份自己的绵薄之力,帮到更多的后来人。
(more…)