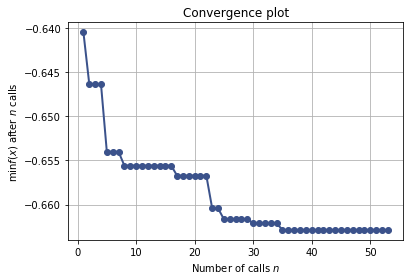
In machine learning models, we often need to manually set various hyperparameters such as the number of trees in random forest and learning rate in neural network. In traditional optimization problems, we can rely on gradient-based approaches to compute optimum. However, hyperparameter tuning is a black box problem and we usually do not have an expression for the objective function and we do not know its gradient. In this post, I will discuss different approaches for hyperparameter tuning and how we can learn to learn.
This is No.11 post in the Connect the Dots series. See full table of contents.
Table of Contents
What exactly is “hyperparameter”? How is it related to so-called “parameter”?
| hyperparameter | parameter | |
|---|---|---|
| manually set by human | yes | no |
| learned from data | no | yes |
| saved as part of the learned model / function | no | yes |
| how to find the optimal values | black box optimization, mostly gradient free – grid search with cross-validation – eblow method in k-means | optimize well-defined objective functions during learning with specific algorithms – iterative gradient-based approach |
| examples | – k in k-nearest neighbor – number of trees in random forest – c and sigma in support vector machine – k in k-means | – coefficients in linear regression model – weights of neural network – support vectors in support vector machine – mean and sigma in Gaussian mixture model |
In summary, hyperparameters are configurations the user defines and are external to the model. Their values cannot be estimated directly from the data and model training.
Hyperparameter tuning is a challenging black box optimization problem
A black box function means we usually do not have an expression for the objective function that we can analyze, and we do not know its derivatives (gradient free). Evaluating the function is restricted to querying at given input hyperparameter \(\lambda\) and data \(D\) and getting a (possibly noisy) response as a function of \(\lambda\). The goal is to minimize the loss function \(L\) with model parameter \(\omega\), hyperparameter \(\lambda\), training data \(D_{train}\), and cross validation data \(D_{valid}\)
$$ \lambda ^* = argmin_{\lambda \in \Lambda} \frac{1}{K} \sum_{i=1}^K \min_{\omega}L(M(\omega, \lambda), D_{train}^i, D_{valid}^i) $$
- \(M\) is a learning model (fitting function) with model parameters \(\omega\), hyperparameter \(\lambda\) with the search space of \(\Lambda\). \(K\) means K-fold cross validation, \(L\) is the loss function with cross validation.
- The goal is to find the best \(\lambda\) that minimizes total loss.
Note that given a fix set of hyperparameters \(\lambda\), the model parameter \(\omega\) is often optimized, using gradient-based approaches we discussed in earlier posts.
A black box optimization problem is challenging [1]:
- There is no explicit expression for the objective loss function. We have no information about its properties, degree of smoothness, derivatives, which can be very helpful in traditional optimization problems.
- The decision variables, here the hyperparameter \(\lambda\) may not be continuous. For example, in k-nearest neighbor, the choice of number of nearest neighbors is a discrete variable.
- In order to estimate the loss on the validation dataset, we need to train a mode, evaluate the results, and update its hyperparameters, which is usually prohibitively expensive and takes long time to run.
Finding good hyperparameters involves solving 2 problems:
- How to efficiently search the space of possible hyperparameters
- How to manage a large set of experiments for hyperparameter tuning
Hyperparameter tuning algorithms and toolkits
Gradient-free algorithms
| type | Python implementation | Scala implementation |
|---|---|---|
| Grid search | scikit-learn https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV | Spark ML https://spark.apache.org/docs/2.2.0/ml-tuning.html |
| Random search | scikit-learn https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html#sklearn.model_selection.RandomizedSearchCV | Customized https://towardsdatascience.com/hyperparameters-part-ii-random-search-on-spark-77667e68b606 |
| Bayesian Optimization | – scikit-optimize https://scikit-optimize.github.io/ – Auto-sklearn https://github.com/automl/auto-sklearn – SMAC https://github.com/automl/SMAC3 – Spearmint https://github.com/JasperSnoek/spearmint | Sigopt https://github.com/sigopt/sigopt-spark – commercial and proprietary – need to use API in Scala Spark |
| Evolution Optimization | deap https://github.com/DEAP/deap – Particle Swarm Optimization – Differential Evolution – Estimation of Distribution Algorithm | note: deap is implemented in pyspark |
Multi-algorithm library
| library | supported algorithm | link |
|---|---|---|
| Google Vizier | Bayesian optimization as the default search algorithm of Google Cloud ML engine | https://cloud.google.com/blog/products/gcp/hyperparameter-tuning-cloud-machine-learning-engine-using-bayesian-optimization |
| Advisor | Google Vizier implementation with API: Grid Search Random Search Bayesian Optimization TPE(Hyperopt) Random Search(Hyperopt) Simulate Anneal(Hyperopt) Quasi Random(Chocolate) Grid Search(Chocolate) Random Search(Chocolate) Bayes(Chocolate) CMAES(Chocolate) MOCMAES(Chocolate) SMAC Algorithm Bayesian Optimization(Skopt) Early Stop First Trial Algorithm Early Stop Descending Algorithm Performance Curve Stop Algorithm | https://github.com/tobegit3hub/advisor |
| Auto-WEKA | Bayesian optimization, Grid search, Multisearch | http://www.cs.ubc.ca/labs/beta/Projects/autoweka/# |
Dive deep in 3 popular algorithms
1. Grid search
Grid search is the most popular and standard hyperparameter search algorithm. We manually set bounds and discretization of the search space, and iterate multiple experiments. Grid search suffers from the curse of dimensionality, but is often embarrassingly parallel because typically the hyperparameter settings it evaluates are independent of each other [2].
2. Random search
Random search replaces the exhaustive enumeration of all combinations of Grid search by selecting them randomly. This can be simply applied to the discrete setting described in the Grid search, but also generalizes to continuous and mixed spaces [3]. It can outperform Grid search, especially when only a small number of hyperparameters affects the final performance of the machine learning algorithm. In this case, the optimization problem is said to have a low intrinsic dimensionality. Random Search is also embarrassingly parallel.
The downside of Random search, however, is that it doesn’t use information from prior experiments to select the next hyperparameter setting. This is particularly undesirable when the cost of running experiments is high and you want to make an educated decision on what experiment to run next. It’s this problem which Bayesian optimization will help solve.
3. Bayesian optimization
The motivation of Bayesian optimization comes from using prior experiments to improve the selection of hyperparameters in subsequent experiments. Since evaluation of the objective function is always expensive, we want to reduce the number of evaluations (i.e. number of experiments).
Bayesian optimization builds a probabilistic model of the function mapping from hyperparameter values to the objective evaluated on a validation set. By iteratively evaluating a promising hyperparameter configuration based on the current model, and then updating it, Bayesian optimization aims to gather observations revealing as much information as possible about this function and, in particular, the location of the optimum. It tries to balance exploration (hyperparameters for which the outcome is most uncertain) and exploitation (hyperparameters expected close to the optimum) [4].
In practice, Bayesian optimization has been shown to obtain better results in fewer evaluations compared to grid search and random search, due to the ability to reason about the quality of experiments before they are run [4].
Bayesian optimization outperforms random search
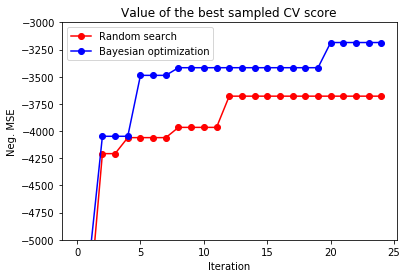
In this example [5], we can see Bayesian optimization reaches better optimum than Random search.
Variations of Bayesian optimizations
There are a lot of variations of Bayesian Optimization. Originally a Gaussian Process Bandit, modified versions such as SMAC [6] and Hyperband [7] have been shown to improve the search.
Bayesian Optimization for any objective function in the pipeline
Bayesian Optimizer takes a history of hyperparameter settings \(\lambda^n = \lambda_i, \lambda_2, …\lambda_n \) and previous function evaluations \(y^i = y_1, y_2, … y_n\) as input and returns a new set of hyperparameters \(\lambda_{n+1}\). \(\lambda_{n+1}\) is then used in model evaluation to generate new function value \(y_{n+1}\). The new hyperparameter and function values are then added to the history for the next iteration \(\lambda^{n+1}, y^{n+1}\).
In practice, Bayesian Optimizer is particular useful for very complex pipelines, such as multi-stage machine learning [9], online A/B test, system configuration [10]. Bayesian Optimizer treats the whole pipeline as a black box and does not care about the details in the pipeline. All it needs is the final objective function to optimize and a history of hyperparameters and function evaluations.
Transfer learning further improves hyperparameter search
Bayesian optimization for hyperparameter tuning suffers from the cold-start problem, as it is expensive to initialize the objective function model from scratch. Transfer learning techniques are proposed to reuse the knowledge gained from past experiences (for example, last week’s graph build), by transferring the model trained before [1]. Thus we can use previous observations as starting points for hyperparameters and search from there, as shown in the diagram below [8].

The mathematical format, code implementation, and examples of Bayesian Optimization will be discussed in the next post.
References
[1] Taking the Human out of Learning Applications A Survey on Automated Machine Learning – Yao – 2018.pdf
[2] Wikipedia https://en.wikipedia.org/wiki/Hyperparameter_optimization
[3] Random Search for Hyper-Parameter Optimization – Bergstra – 2012.pdf
[4] A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning – Brochu – 2010.pdf
[5] Github http://krasserm.github.io/2018/03/21/bayesian-optimization/
[6] Sequential Model-Based Optimization for General Algorithm Configuration – Hutter – 2011.pdf
[7] Hyperband- A Novel Bandit-Based Approach to Hyperparameter Optimization – Li – 2018.pdf
[8] Transfer learning https://machinelearningmastery.com/transfer-learning-for-deep-learning/
[9] Google Cloud ML https://cloud.google.com/blog/products/gcp/hyperparameter-tuning-cloud-machine-learning-engine-using-bayesian-optimization
[10] Facebook https://research.fb.com/efficient-tuning-of-online-systems-using-bayesian-optimization/