
In the past 2 years, I have been following progress in Reinforcement Learning (RL). RL beats human experts in Go [1], and achieves professional levels in Dota2 [2] and StarCraft [3]. RL is being mentioned more and more often in mainstream media and conferences.
I think it is a good time for me to revisit RL.
The first time I heard “Reinforcement Learning” was when I was interviewing for a summer internship in early 2017. At the final round with the VP of data science, he casually asked “Have you heard of reinforcement learning?” I shook my head. He then gave me a very brief introduction of RL and said he has been watching a tutorial recently. After the interview when I got back home, I sent him an email and asked for the tutorial’s link. Turns out it was David Silver’s famous RL course on YouTube [4]. I finished the course, and started to read the classic RL textbook by Andrew Barto and Richard Sutton [5]. When I started my internship in the same company, I gave RL workshops to my coworkers and discussed potential applications of RL.
In the next few posts, I will talk about RL basics using the slides I made in 2017, and summarize most recent progress in RL.
Table of Contents
Trial-and-error learning
A baby giraffe learns to stand up by itself immediately after birth without too much guidance, through trial and error. We human beings learn and make decision mostly through experience and trial and error as well. In robotics, autonomous helicopters learn to performing an aerobatic airshow using trial-and-error based RL.
What does this have to do with RL?
RL is different from supervised learning because RL does not have a supervisor or a classifier overseeing the whole process. Also, RL is different from unsupervised learning because RL has intrinsic preference and values which guide the agent to make decisions.
RL attracts increasing attention in both academia and industry
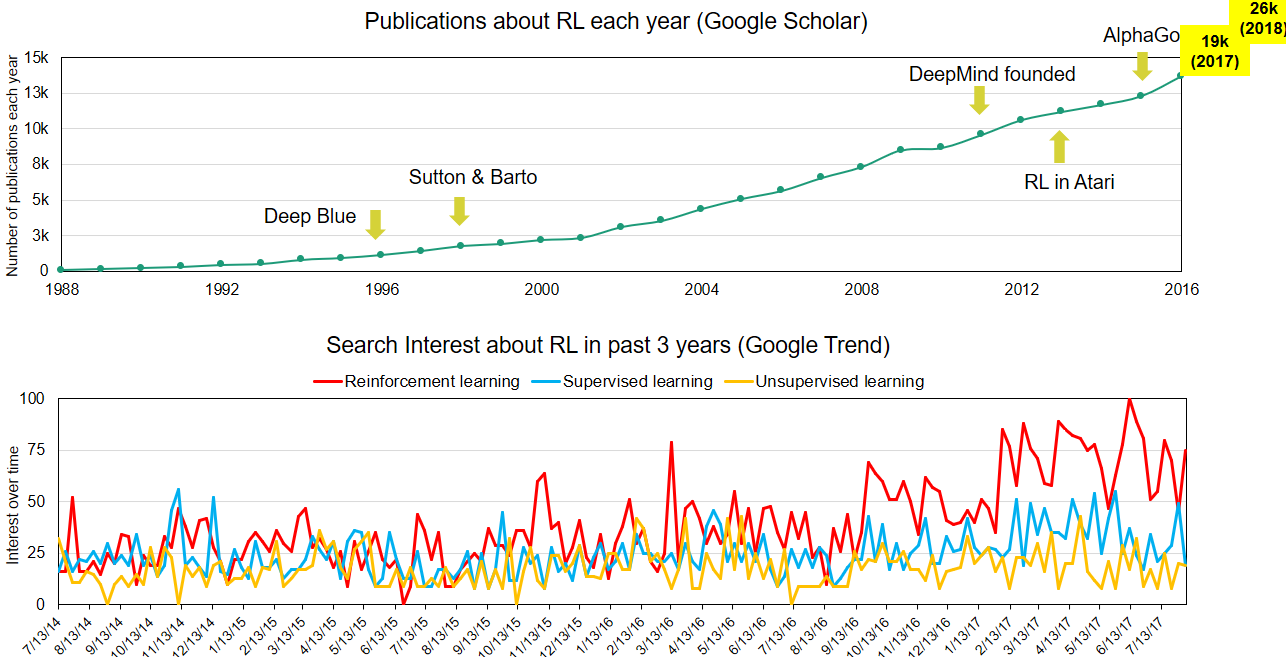
Google Scholar chart shows increasing annual publications related to RL since the 1980s. Also, 20 years after Deep Blue used brutal force to defeat the best human chess player, AlphaGo used RL and defeated the best human Go player. In recent years, the development of deep learning and neural network fuels RL with more power. I added the data of 2017 and 2018 (yellow box) to the slide that I made in 2017. In 2018, there were about 26,000 publications related to RL, twice the number in 2016.
Google Trend shows the search interest of RL exceeds supervised learning and unsupervised learning since 2016.

RL has attracted many early adopters, in both tech industry and finance (data until June 2017). More and more companies are using RL to tackle real-world problems.
RL is an interdisciplinary field
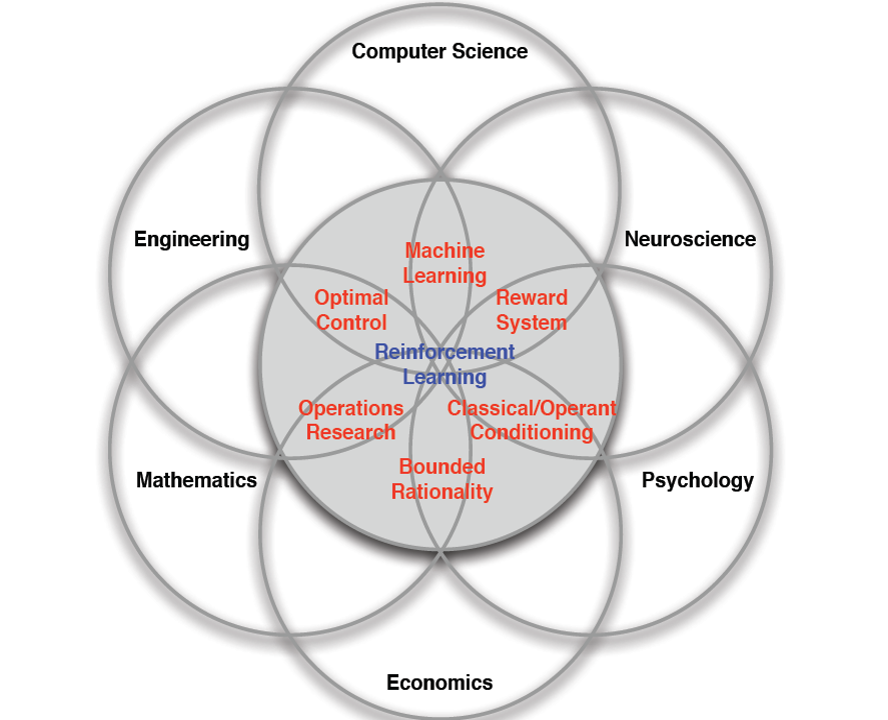
I really like this venn diagram from David Silver’s course [4]. It captures the very distinct aspect of RL: it has something to do with many things! As a neuroscientist, I find RL particularly intriguing as it not only mimics how human learns, but also integrates research from other fields, helping us better understand human brain and machine learning.
RL is a sequential decision making process
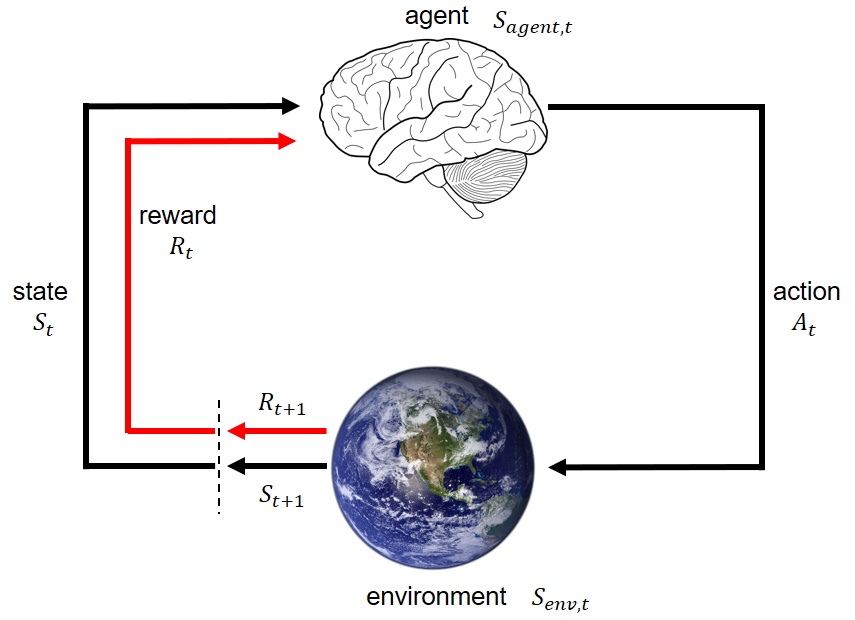 This is a classic RL diagram showing the interaction between the learning agent and the environment. At time \(t\), the agent perceives state \(S_t\) and reward \(R_t\) from the environment, and takes an action \(A_t\), which will affect the state of the environment. The environment, at time \(t+1\), generates another state \(S_{t+1}\) and reward \(R_{t+1}\). The agent evaluates the goodness of a state using value function, and makes decisions according to a policy. The environment determines the transition probability from one state to a successor state, and the immediate reward. The final goal of the agent is to maximize total future reward.
This is a classic RL diagram showing the interaction between the learning agent and the environment. At time \(t\), the agent perceives state \(S_t\) and reward \(R_t\) from the environment, and takes an action \(A_t\), which will affect the state of the environment. The environment, at time \(t+1\), generates another state \(S_{t+1}\) and reward \(R_{t+1}\). The agent evaluates the goodness of a state using value function, and makes decisions according to a policy. The environment determines the transition probability from one state to a successor state, and the immediate reward. The final goal of the agent is to maximize total future reward.
Overall, RL represents a complex sequential decision making process.
In the next post, I will discuss Markov Decision Process and RL agent.
References
cover photo from https://youtu.be/v9FunBolqvA
[1] AlphaGo Zero: Learning from scratch, https://deepmind.com/blog/alphago-zero-learning-scratch/
[2] OpenAI Five 2018 https://openai.com/blog/openai-five/
[3] AlphaStar: Mastering the Real-Time Strategy Game StarCraft II, https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
[4] RL course by David Silver https://youtu.be/2pWv7GOvuf0
[5] Reinforcement Learning: An Introduction
Book by Andrew Barto and Richard S. Sutton