 In the previous post,I gave a high-level overview of Reinforcement Learning (RL). In this post, I will summarize different learning paradigms of RL agents.
In the previous post,I gave a high-level overview of Reinforcement Learning (RL). In this post, I will summarize different learning paradigms of RL agents.
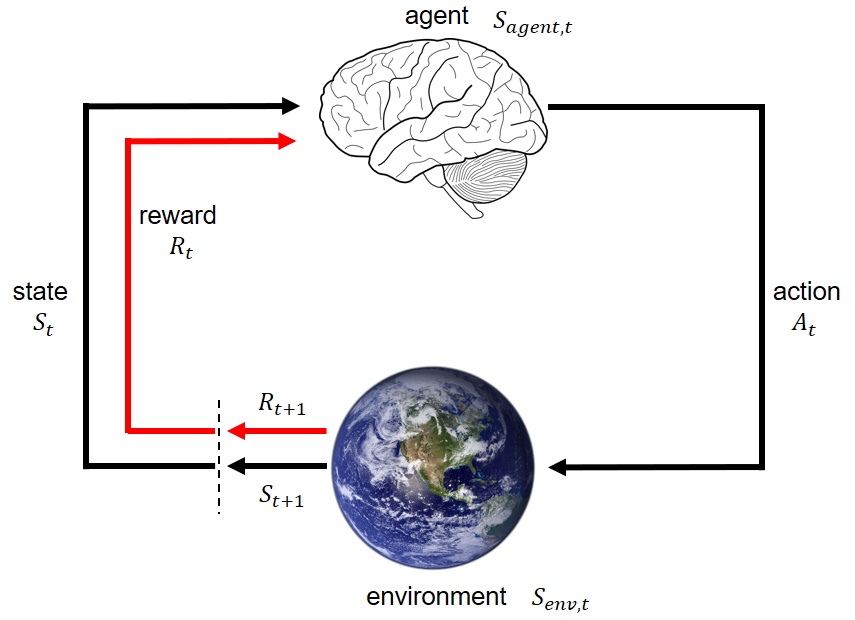
RL is a sequential decision making process. At time \(t\), the agent perceives state \(S_t\) and reward \(R_t\) from the environment, and takes an action \(A_t\), which will affect the state of the environment. The environment, at time \(t+1\), generates another state \(S_{t+1}\) and reward \(R_{t+1}\).
Objective of an RL agent

The final goal of an RL agent is to maximize total future reward after a series of states and actions.
Markov Decision Process
One assumption in RL is that this sequential decision making process is a Markov Decision Process (MDP). MDP says the future state is completely decided by the present state, and is irrelevant of the previous states. This means in order to decide which action to take next, we only need to evaluate the present state, without the need to remember the whole history.

MDP is defined by a 5-variable tuple, as shown above. \(S, A\) capture all possible states and actions the RL agent can take, \(P, R\) captures the effect of the environment on the RL agent, and \(\gamma\) captures the temporal discount of reward over time.
Value, Policy, and Model
The sequential decision making of an RL agent can be illustrated in the following diagram.
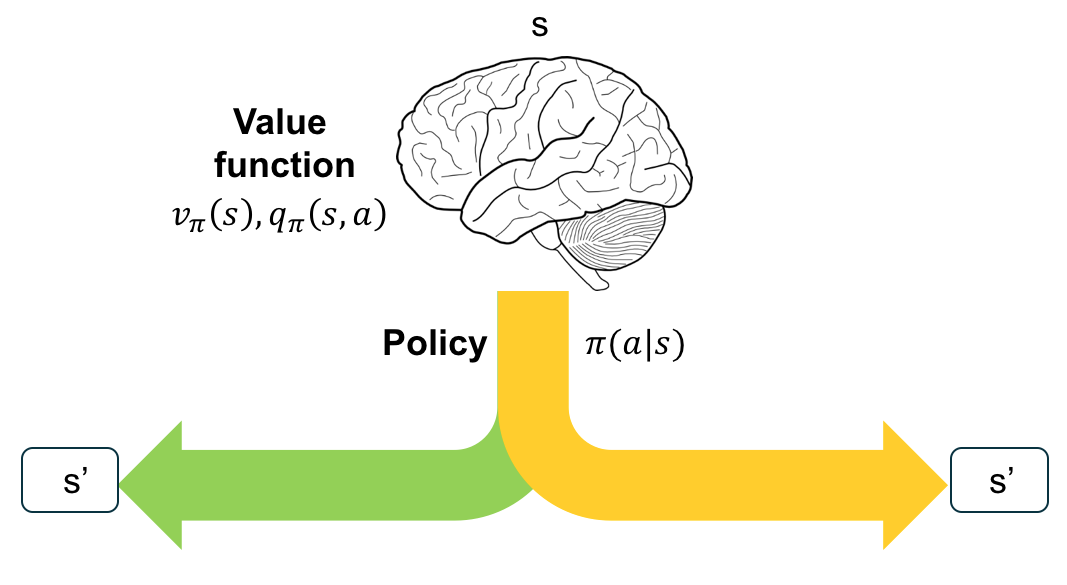
The agent is at state \(s\). It makes a decision to take an action \(a\) to go to the next state \(s’\). The probability of taking an action \(a\) at state \(s\) is given by a policy \(\pi\).
The agent evaluates the goodness of a state using value function. The value function either evaluates a particular state \(v(s)\) or both the state and an action \(q(s,a)\).
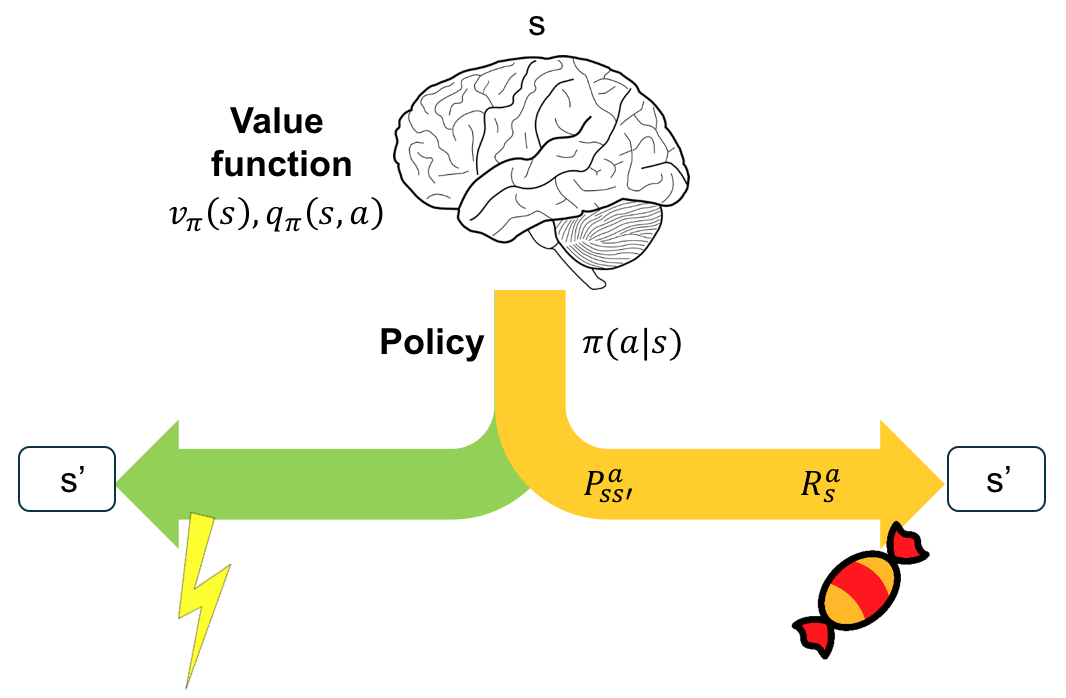
The environment determines the transition probability from one state to a successor state \(s’\), and the immediate reward \(R_{s}^a\). In the diagram above, one successor state is preferable with better reward (candy), while the other successor state is less preferable (electric shock). After taking an action \(a\), the agent has a probability of \(P_{ss’}^a\) ending up in the candy state.
Both the transition probability and reward from the environment is unknown to the agent. As a result, the agent perceives the environment as it goes.
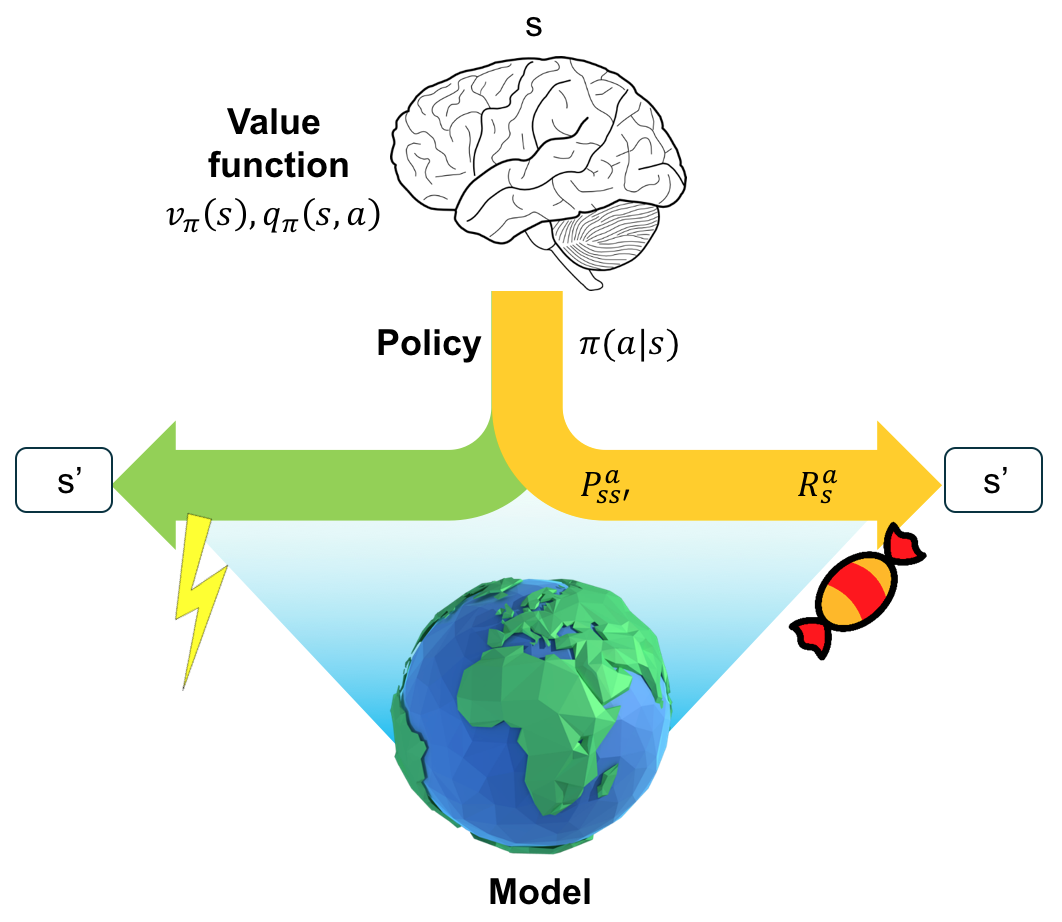 In contrast, an RL agent can learn to build a model (the cartoonized earth) of the environment and use the model to simulate transition probability and reward, without having to go through the actual action and consequences.
In contrast, an RL agent can learn to build a model (the cartoonized earth) of the environment and use the model to simulate transition probability and reward, without having to go through the actual action and consequences.
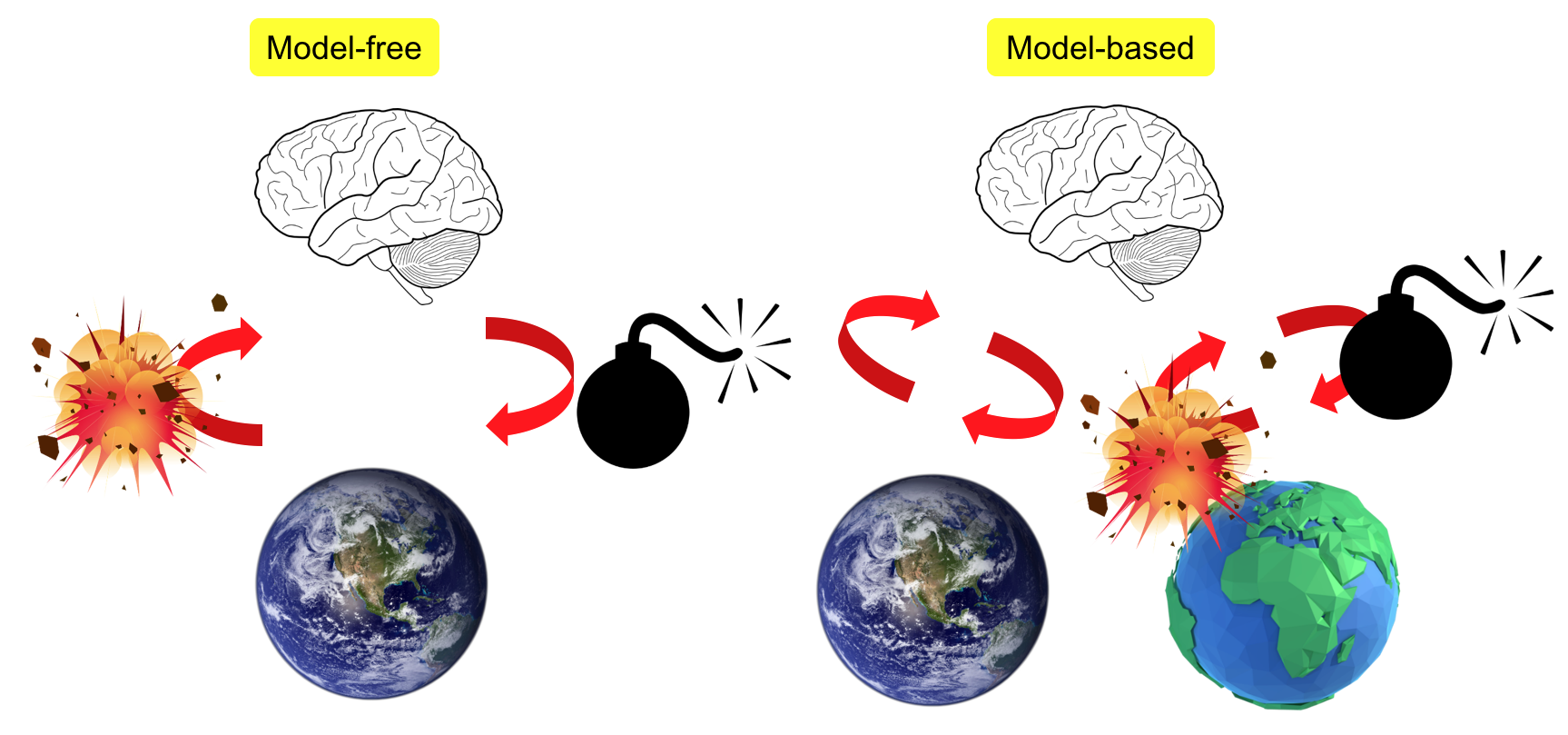
The difference between model-free and model-based RL learning paradigm is shown in the above figures. On the left, the agent learns by doing. In this case, the agent lights up a bomb. The environment then explodes, and the agent is destroyed. Model-free RL interacts with the real environment and relies on real environment feedback and reward for learning, and as a result, it may take irreversible and disruptive actions. On the right, the agent constructs a simulated model first. The information an agent receives from the environment for a given state and action is transition probability and reward. Thus, the agent needs to build a predictive model for \(P_{ss’}^a\) and \(R_s^a\). The agent then may light up a bomb in this simulated environment, and learn that lighting up a bomb would result in explosion in this simulated environment. Thus it will not take such action in the real environment. Although model-based RL helps protect unexpected actions and states, the simulated environment is never perfect, and can be biased.
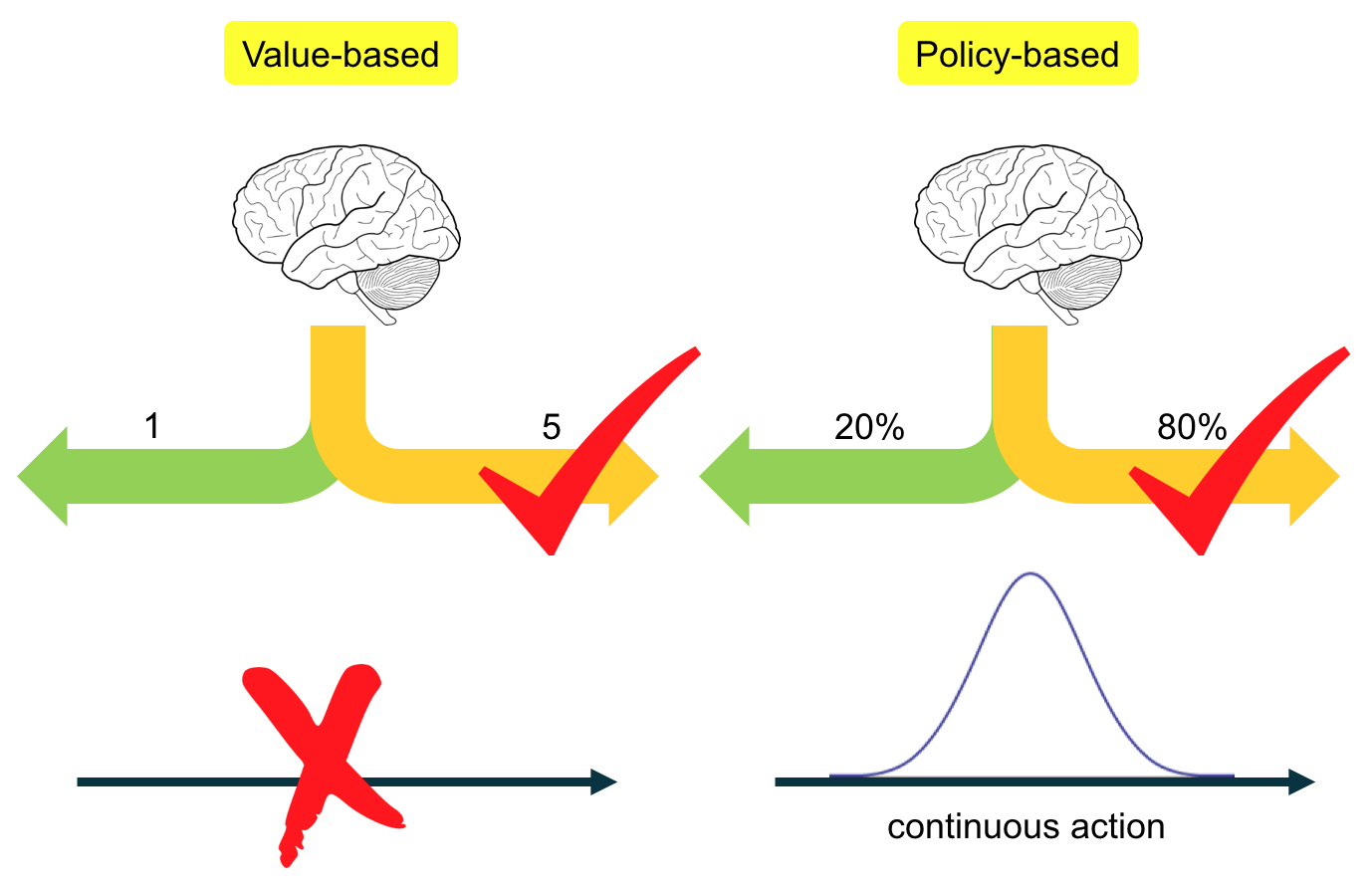
Depending on how the agent decides to take an action, model-free RL is categorized as value-based RL and policy-based RL.
- Value-based RL learns the value function \(v(s)\) and selects the action that maximizes the value \(argmax_a v(s)\).
- Policy-based RL learns the policy function \(q(s,a)\) which selects each action with certain probability. It is thus less deterministic and more explorative.
- In addition, only policy-based RL is capable to representing a continuous action space using probability.
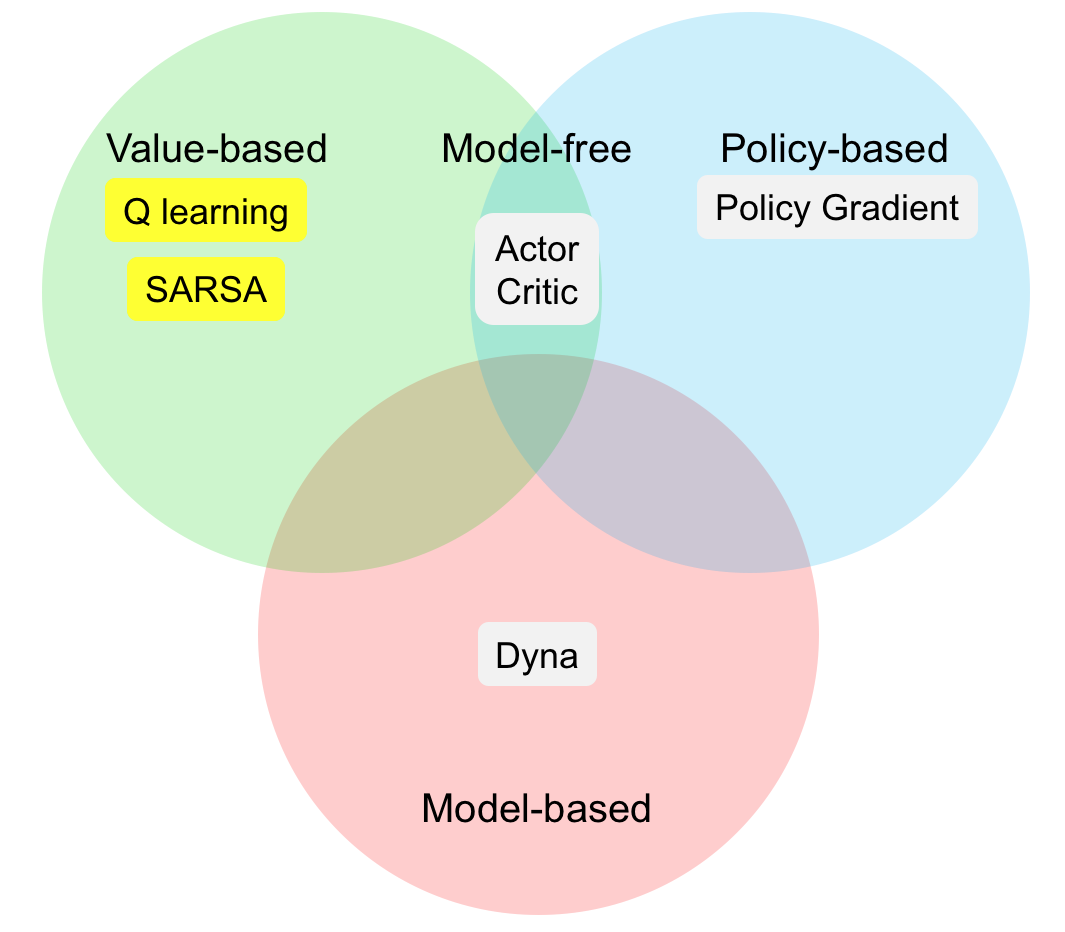
To recap, as shown in the venn diagram above, there are different types of RL agents based on model, value, and policy. Most RL agents are model-free, including value-based and policy-based RL. Each type of RL agents has several classic algorithms which will be covered in later posts.
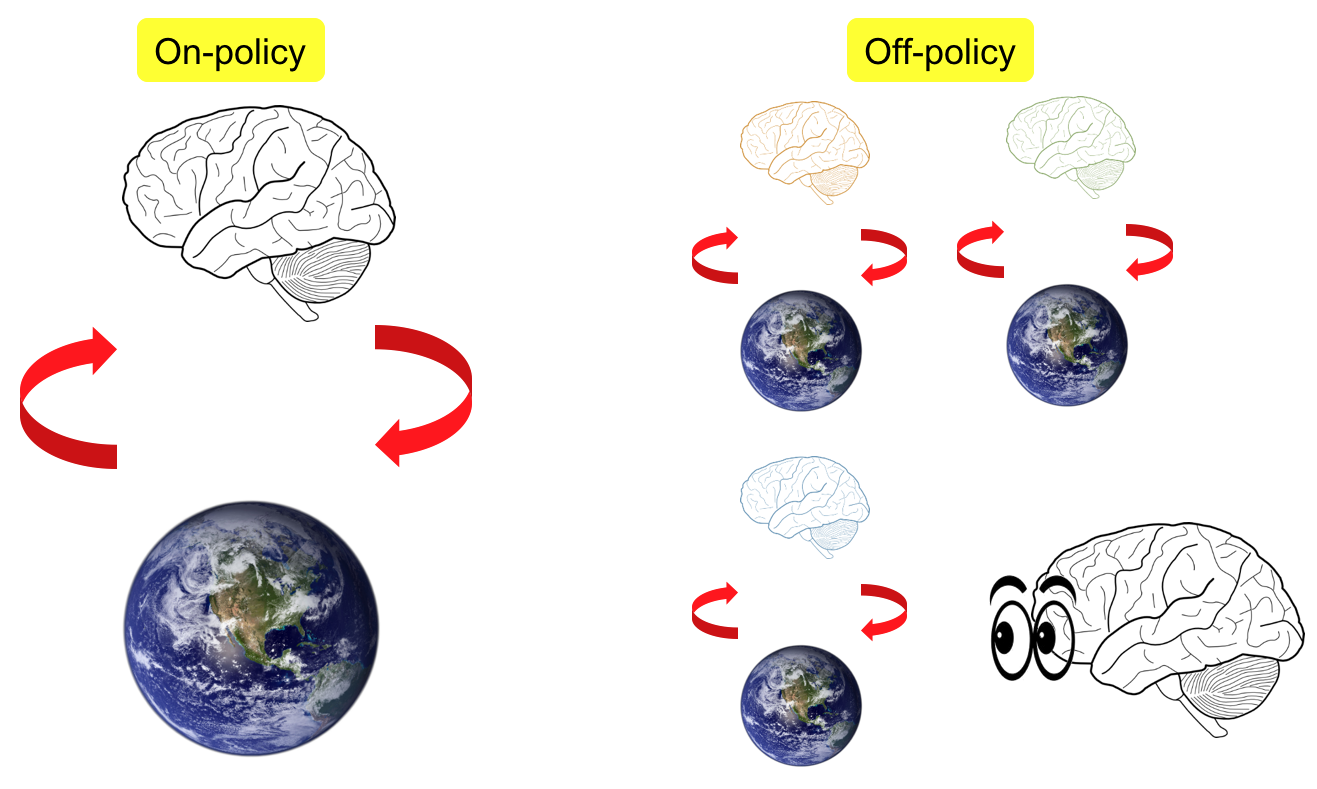
Depending on how the agent learns about the environment, RL agent is categorized as on-policy learning and off-policy learning. On-policy RL learns by itself, while off-policy RL learns by examples from other agents.
Now think about how we humans learn. We learn from others to gain experience (off-policy), as well as from our own experience (on-policy). We learn from doing and interacting with the real world (model-free), as well as theorizing in our mind before taking an action (model-based)
In the next post, I will discuss in detail how model-free RL learns.
Reference
Some figures and diagrams in this post are modified from Mofan’s series on RL https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/ and RL course by David Silver https://youtu.be/2pWv7GOvuf0