
In the previous post, I introduced challenges in machine learning systems with big data and complex models. In this post, I will discuss distributed systems in the era of big data.
Table of Contents
Distributed systems
Before we talk about what is distributed model training, let’s first review distributed systems.
Back in the early 2000s when Google search started to take off and become the most popular search engine with its PageRank algorithm, engineers at Google realized the challenges of storing and processing large amount of webpage index data on multiple servers. In 2003 they invented the Google File System (GFS) [1] to store big data with fault-tolerance, consistency, replication, and parallel performance.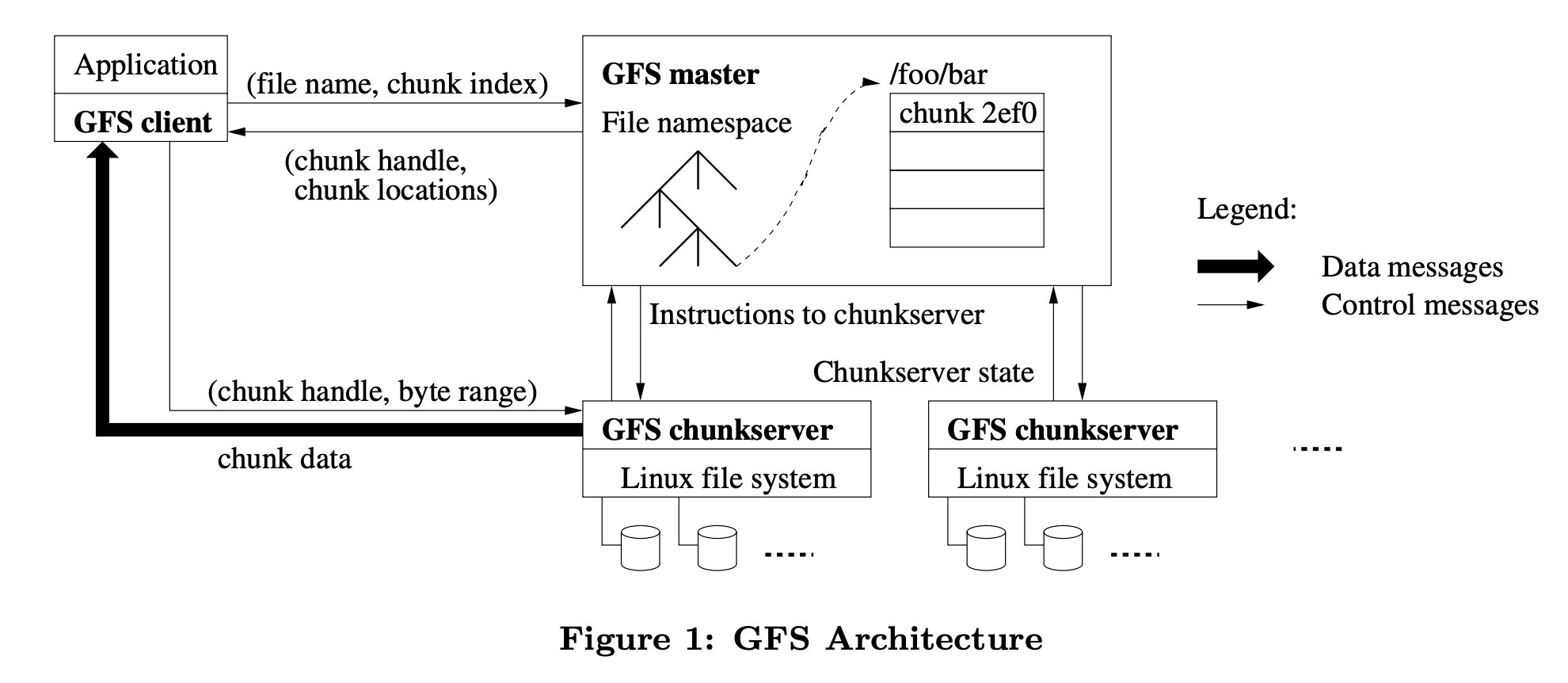
The system is consisted of one master (naming) server and multiple chunkservers. The master server keeps the state of chunkservers in RAM and on disk for failure recovery, while the data are shared in big chunks on workers with replication.
In the following year 2004, Jeff Dean and Sanjay Ghemawat at Google proposed the MapReduce model [2] to handle parallel computing and to provide easy-to-implement abstraction for non-specialist programmers to process big data with custom-defined Map and Reduce functions.
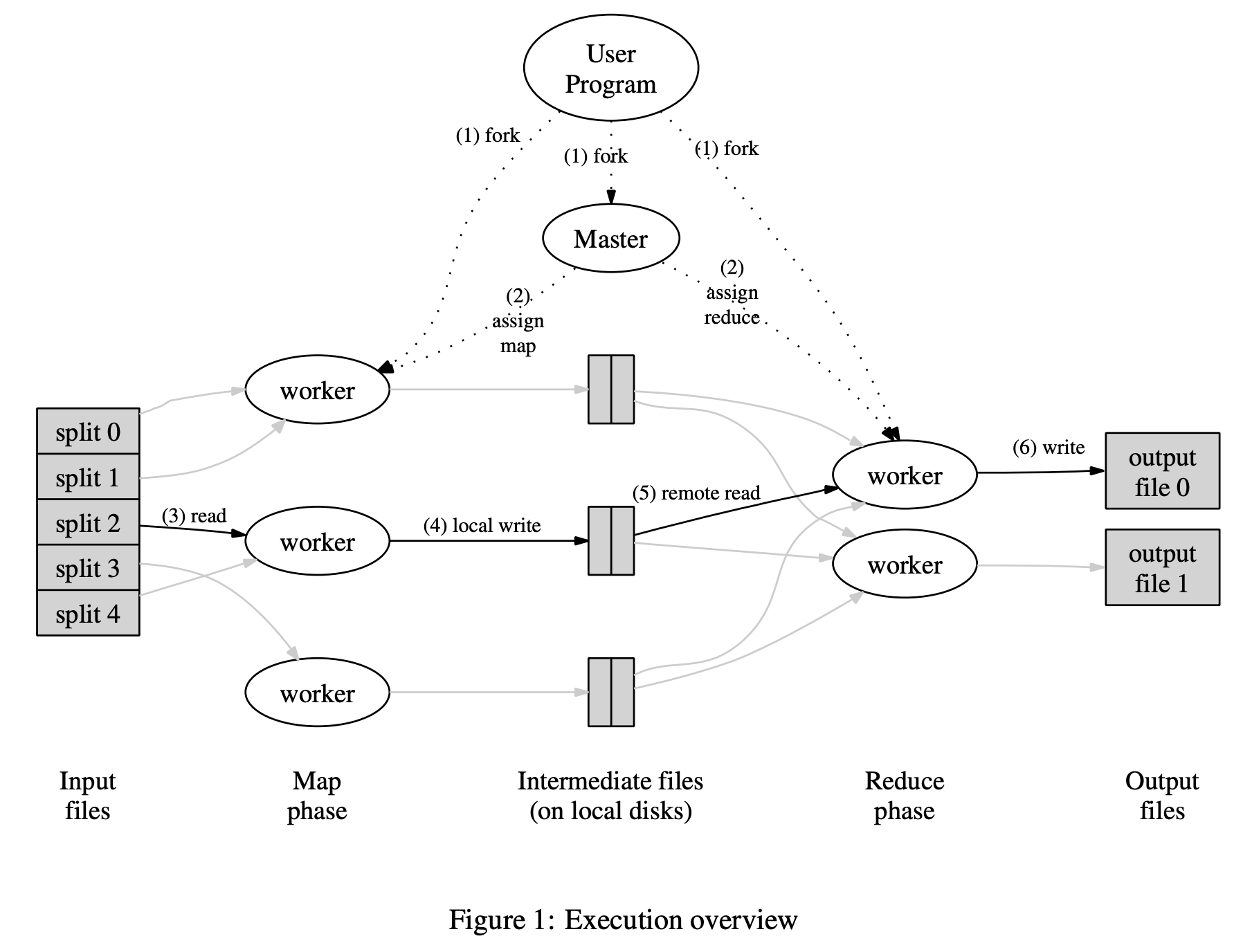
Using GFS, data are shared and stored on disk on different workers. Map function runs on the same worker that stores the shared data in parallel, and outputs intermediate files on local disk. These intermediate files are then passed to the Reduce workers where the Reduce function runs and outputs the final files in local disk on many Reduce workers in parallel. All workers are coordinated by the master server. Using MapReduce, we could achieve N times throughput by having N workers running in parallel.
MapReduce in distributed model training
Using the MapReduce strategy, if we can split the training data on separate workers, compute Map functions in parallel, and aggregate the results in a Reduce function, we will be able to achieve distributed model training directly.
For example, to train a Linear Regression model, we can solve the function by minimizing the least square error and get a closed-form solution:
\(\hat \theta = ( \textbf{X}^T \textbf{X}) ^ {-1} \textbf{X}^Ty \tag{1} \)
See detailed computation in my previous post on linear regression.
The estimated parameter \(\hat \theta\) can be decomposed into 2 parts below, each can be written as a summation format:
\(\textbf{X}^T \textbf{X} =\sum_{i=1}^{N}(x_i x_i^T) \tag{2}\)
\(\textbf{X}^Ty =\sum_{i=1}^{N}(x_i y_i) \tag{3}\)
Therefore, we can potentially shard our training data on different workers, compute them in parallel, and then combine the results to get \(\textbf{X}^T \textbf{X}\) and \(\textbf{X}^Ty\), as shown in the example below from Andrew Ng’s course [3].
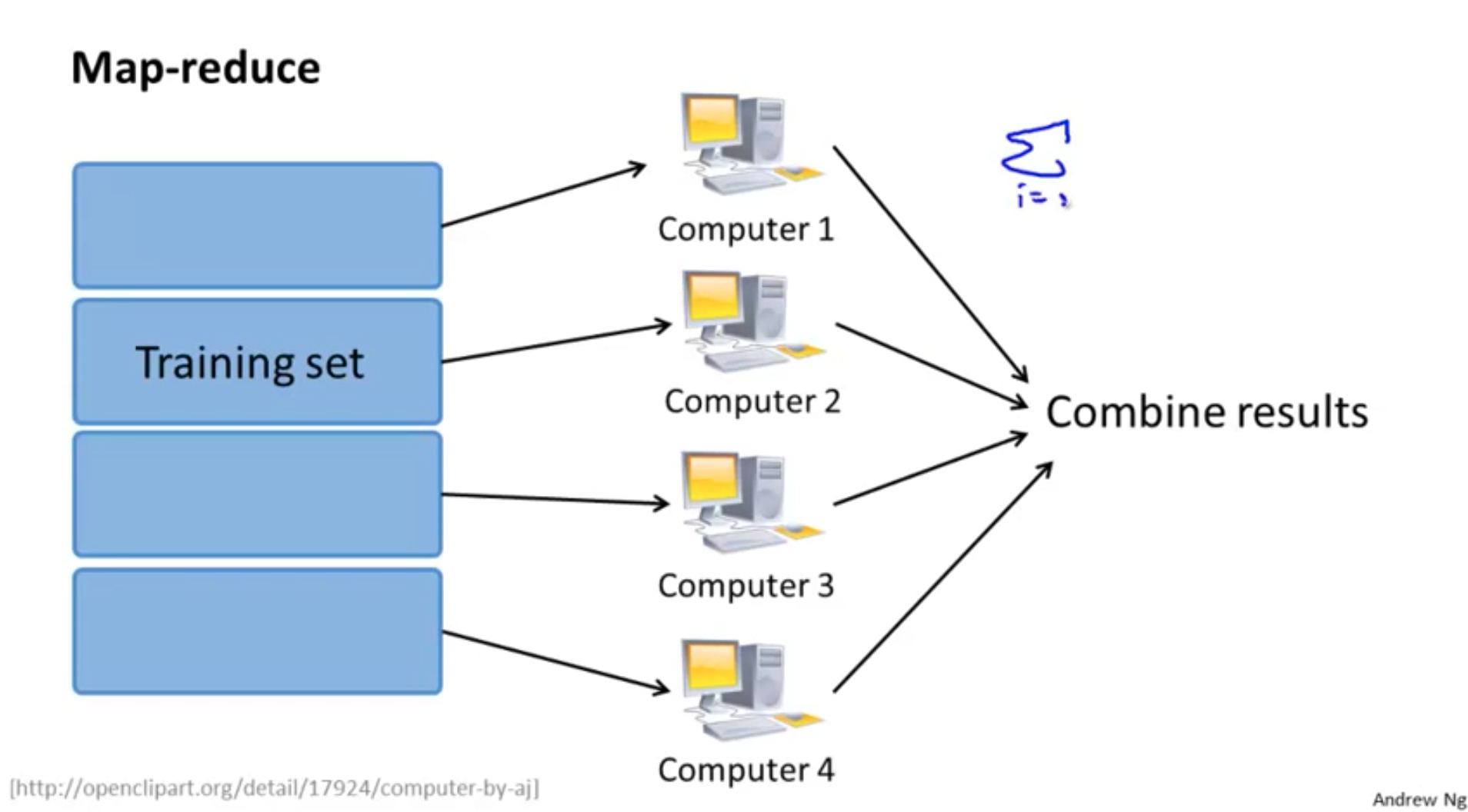
When n is much larger than p, the computation cost is dominant by the matrix summation computation, whiles matrix inversion and multiplication is less significant [4].
\(A = \textbf{X}^T \textbf{X} =\sum_{i=1}^{N}(x_i x_i^T) => O(np^2)\)
\(C = \textbf{X}^Ty =\sum_{i=1}^{N}(x_i y_i) => O(np) \)
\(B = A^{-1} => O(p^3)\)
\(BC => O(p^2)\)
In summary, we can use MapReduce to achieve distribute model training if we have a summation form solution and a large amount of training data with relatively few numbers of features.
MapReduce for iterative training
Most machine learning algorithms do not have a closed-form solution and are usually done through iterations with gradient descent. Gradient is usually computed by summing up the gradient of all the data point [4].
\(w = w – \alpha g \tag{4} \)
\(g = \frac{1}{N}f_w(x_i, y_i) \tag{5}\)
Because of the summation format in formula (5), theoretically speaking, we can use MapReduce to distribute the computation of gradients on sharded data and then get the combined results to update the gradient .
However, MapReduce is not well suited for iterative algorithms. As shown in the diagram below [4] , in each iteration, Map workers read all the data from disks (eg: GFS), and Reduce workers write updated weights to local disks. The system is repeatedly loading the same data and saving intermediate output between stages, which is unnecessary and slow.
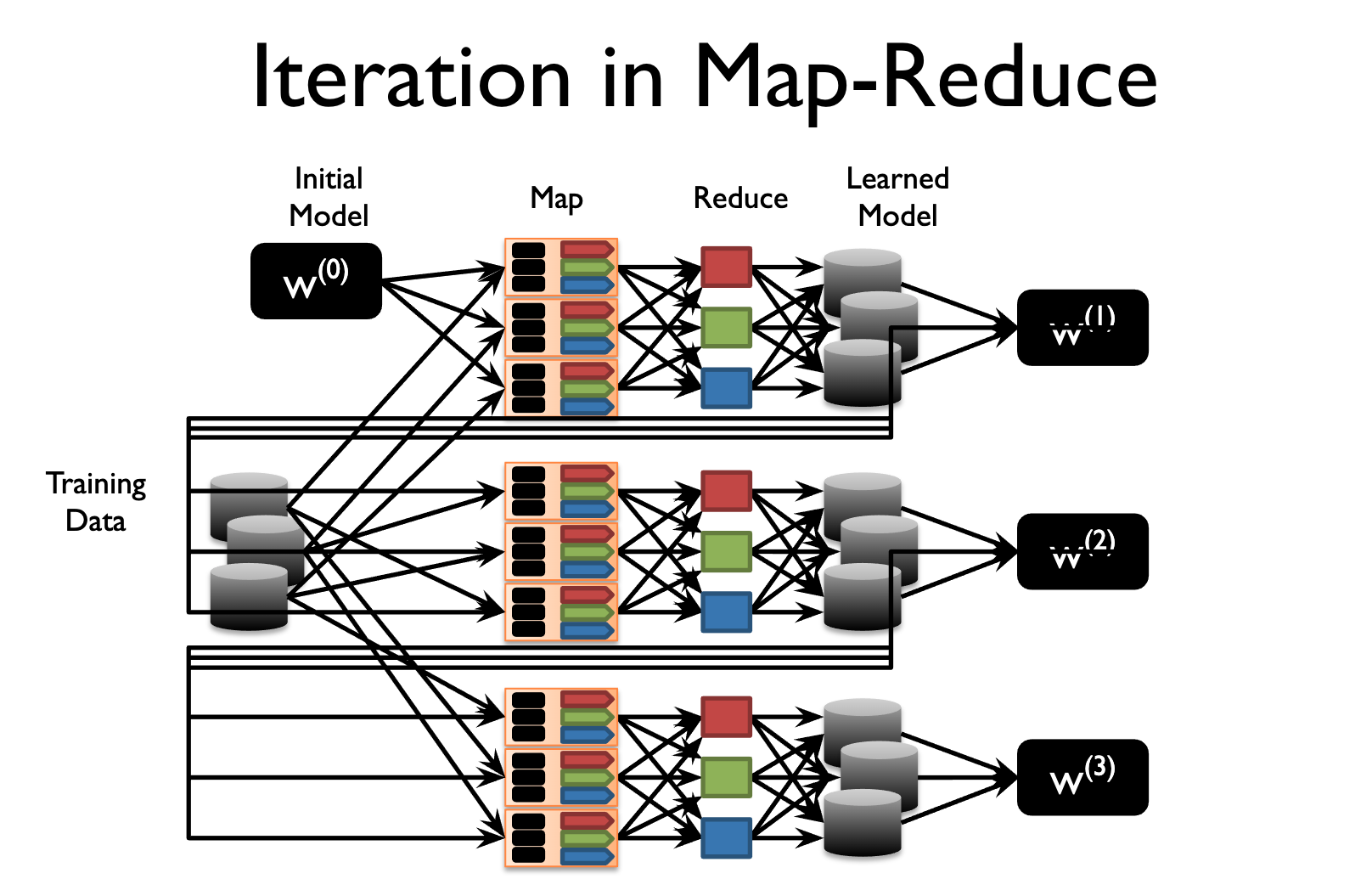
As a result, in practice, MapReduce is not commonly used in distributed model training.
Spark for iterative model training
8 years after MapReduce was invented, in 2012, Zaharia et al. proposed a novel in-memory cluster computing model “Spark” to support fast iterative training [5]. Spark generalizes MapReduce into dataflow and creates a lineage graph with multi-step transformation.
 Spark keeps persistent RDDs in memory by default between transformation and across iteration using Resilient Distributed Datasets (RDDs) abstraction. Compared to MapReduce with repeated I/O, Spark improves performance greatly.
Spark keeps persistent RDDs in memory by default between transformation and across iteration using Resilient Distributed Datasets (RDDs) abstraction. Compared to MapReduce with repeated I/O, Spark improves performance greatly.
Ever since its launch, Spark and its MLlib library have been widely used to perform distributed big data model training. See my previous post on Spark.
In the next post, I will continue discussing distributed model training with deep neural network and parameter servers.
References
cover image https://pixabay.com/illustrations/big-data-data-analysis-information-1084656/
[1] https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
[2] https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
[3] https://www.coursera.org/lecture/machine-learning/map-reduce-and-data-parallelism-10sqI
[4] https://ucbrise.github.io/cs294-ai-sys-fa19/
[5] https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
Great post! I have been noticing you for a long time and looking forward to more sharing:)