第一次在职跳槽总算完成了!在面试准备的过程中,我学到了不少工作之外的知识和技能,这里分享一下我的跳槽经验。下周入职新公司Spotify的Machine Learning Engineer职位。

This summer, I volunteered to be a mentor for a data science intern. It reminds me of my own internship 2 years ago, when I learned so much from my mentor (see my previous posts). Being a mentor not only allows me to view a summer internship from the other side of the table, but also presents new challenges and learning opportunities for myself. In this post, I will share some tips for first-time mentors from my experience as a first-time mentor.
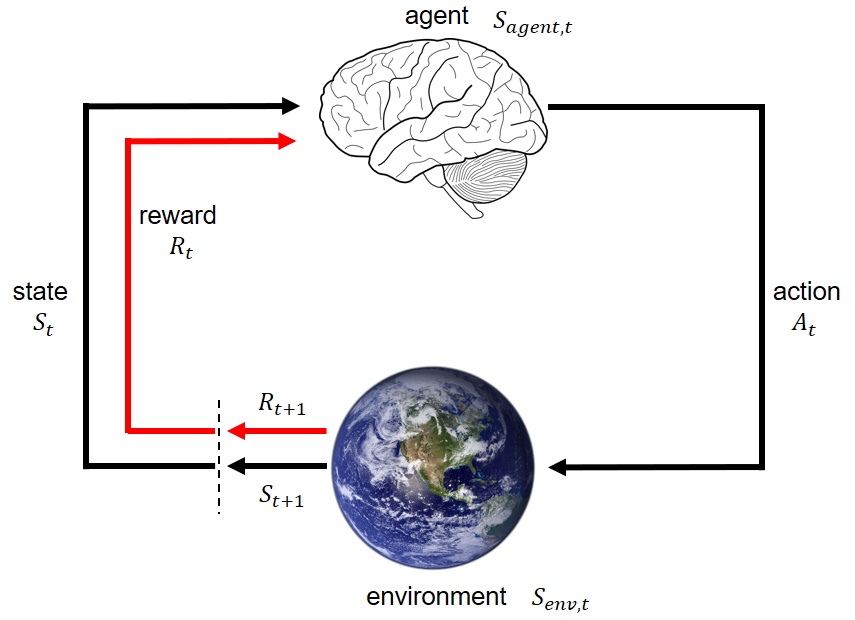 In the previous post,I gave a high-level overview of Reinforcement Learning (RL). In this post, I will summarize different learning paradigms of RL agents. (more…)
In the previous post,I gave a high-level overview of Reinforcement Learning (RL). In this post, I will summarize different learning paradigms of RL agents. (more…)

In the past 2 years, I have been following progress in Reinforcement Learning (RL). RL beats human experts in Go [1], and achieves professional levels in Dota2 [2] and StarCraft [3]. RL is being mentioned more and more often in mainstream media and conferences.
I think it is a good time for me to revisit RL. (more…)

Now that we have done most of the hard work: numerous experiments, survey, coding, refactoring, pipelining, analysis, visualization, charts, numbers, written documents and so on, we are going to give a final presentation. “That’s easy,” one may think, “Just paste my results into PowerPoint slides and click through it.”
Having seen quite a lot of presentations at conferences, group meetings, and tech demos, and having given many presentations myself in different scenarios, one thing I can say for sure about presentations is that “It is not easy” at all. It is as demanding as most of the hard work we have done, and requires similar learning and practice as coding, analysis, and writing. In this post, I will summarize what I learned from my mentors, teachers, peers, as well as my own mistakes about presentations.

Last month, I went to Long Beach, California to attend the 36th international conference machine learning (ICML). Having been to several academic conferences during graduate school in neuroscience (SfN) and biophysics (BPS), I was very excited to go to a comprehensive machine learning conference for the first time. Here are my key takeaways and favorite talks at ICML 2019.
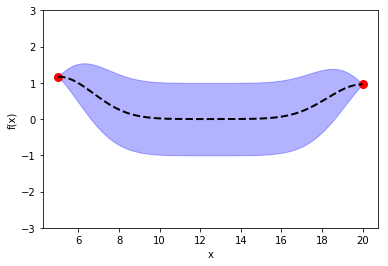
In the previous post, I introduced Bayesian Optimization for black-box function optimization such as hyperparameter tuning. It is now time to look under the hood and understand how the magic happens.
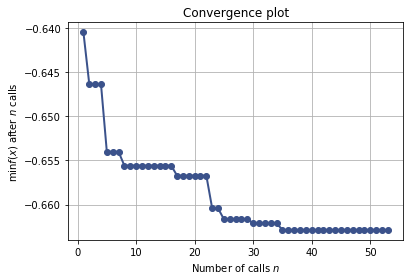
In machine learning models, we often need to manually set various hyperparameters such as the number of trees in random forest and learning rate in neural network. In traditional optimization problems, we can rely on gradient-based approaches to compute optimum. However, hyperparameter tuning is a black box problem and we usually do not have an expression for the objective function and we do not know its gradient. In this post, I will discuss different approaches for hyperparameter tuning and how we can learn to learn.