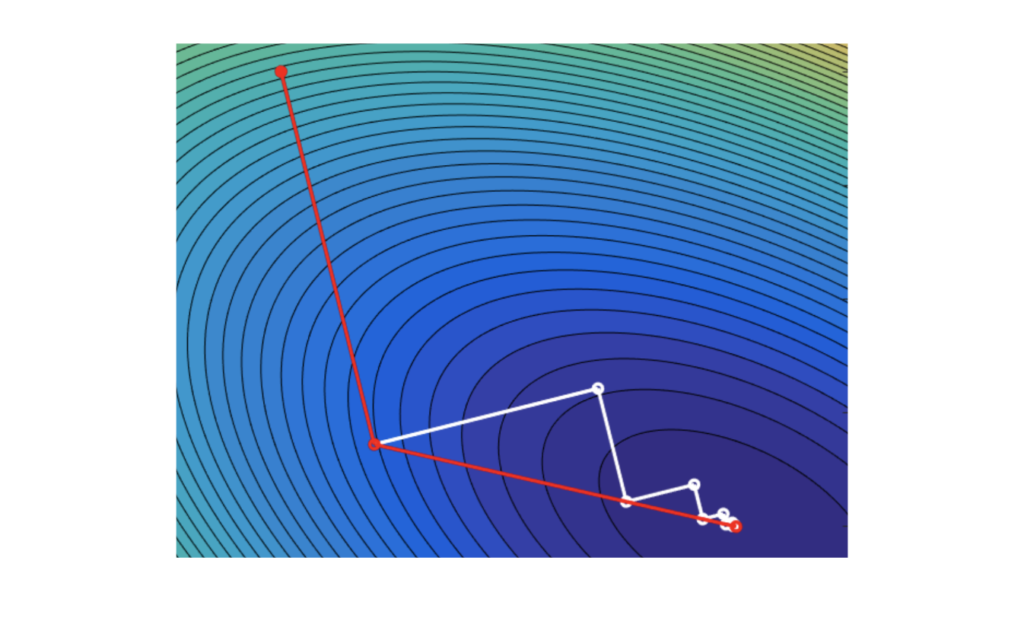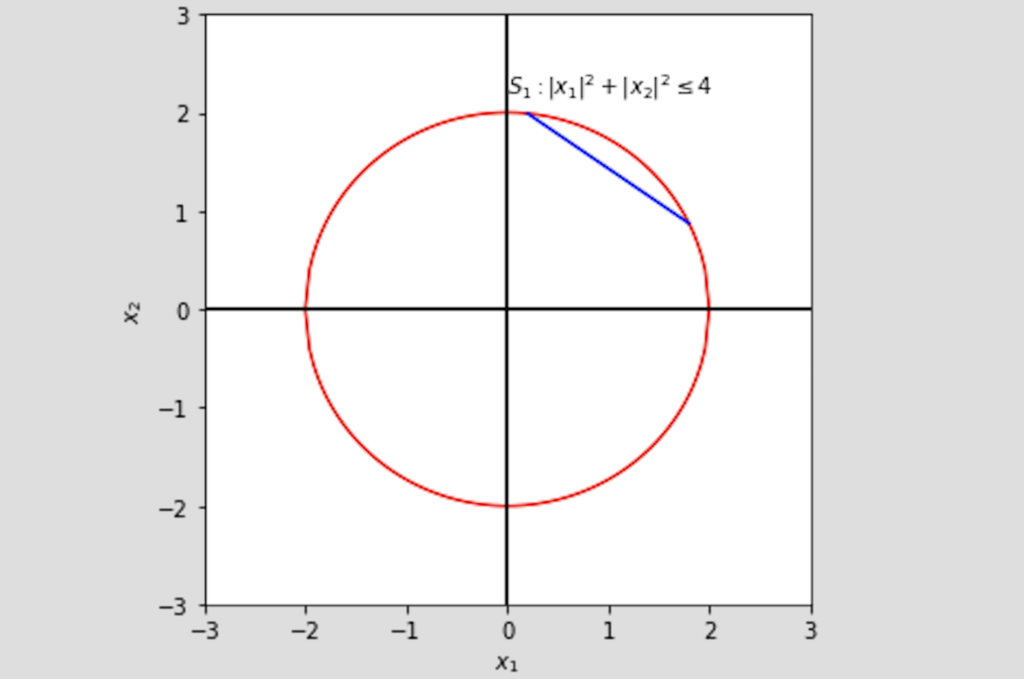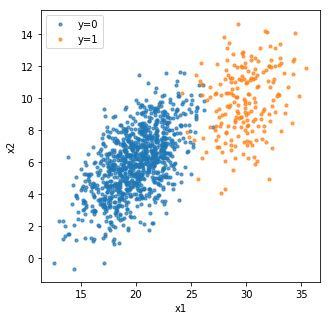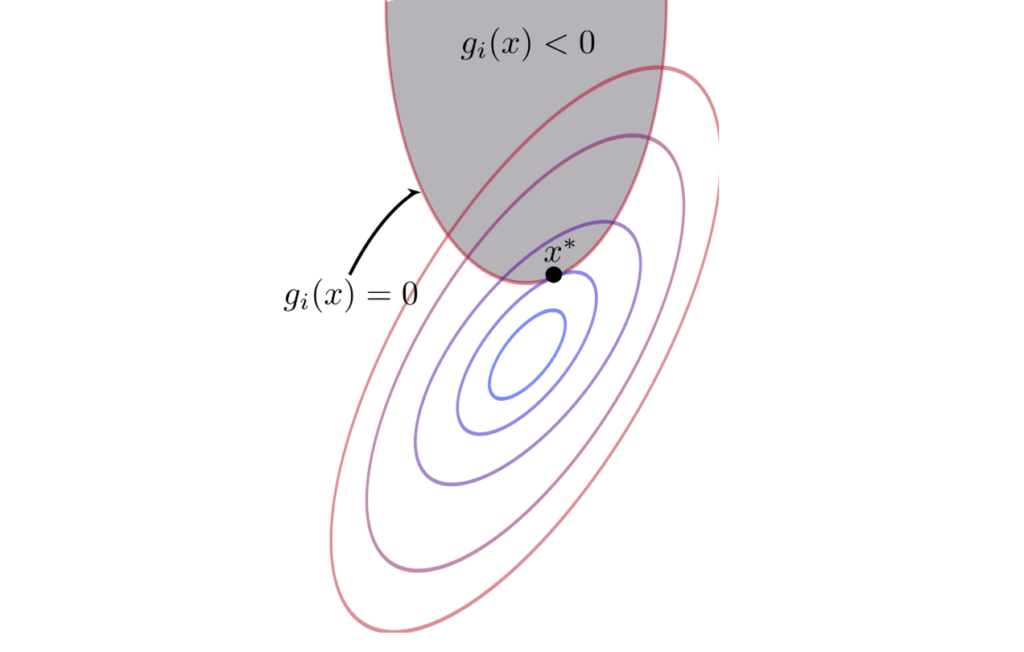
Now what we have discussed unconstrained optimization problems in previous post, it is now time to come to the reality. In the real world, we often have limitations, such as the total budget, motion angles, and some arbitrary desirable range of values. Life would be so easy (and boring) without boundary and conditions. Adding constraints certainly makes optimization problems less easy, but more interesting.